Paper Reading — Do Vision Transformers See Like Convolutional Neural Networks?

The Vision Transformer (ViT) has gained huge popularity ever since its publication and showed great potential over CNN-based models such as ResNet. But why is the Vision Transformer better than the CNN models? One recent publication, Do Vision Transformers See Like Convolutional Neural Networks? suggests that the advantages of ViT come from the following perspectives:
- The features across different layers of ViT are more uniform, while features from different layers of CNN models have a grid-like pattern;
- The attention from lower layers of ViT contains global information, while the nature of CNN only attends locally in lower layers;
- The skip connection takes a prominent role in information propagation at higher layers of ViT, while the ResNet/CNN skip connections pass less information at higher layers;
- Besides, the scale of data, and the usage of global average pooling, will both form a great impact on the representation of ViT.

First, let’s take a look at two architectures below, the ViT and a typical CNN model, the ResNet50. The ResNet50 takes in the whole dog image and performs 2D convolution with kernel size 7*7; with 50 layers stacked by residual blocks, a global average pooling block and a dense layer are attached to the end to classify the image as “dog”. The ViT first breaks the dog image into 16*16 patches, treats each patch as a “token”, then sends the whole sequence of tokens into the transformer encoder, which is comprised of multi-head self-attention blocks; the encoder features are then sent into the MLP layer for classification for the class “dog”.

For two feature vectors of different lengths, it’s hard to measure their similarity. Hence the authors proposed a special metric, the Centered Kernel Alignment (CKA), which is used throughout the whole paper. Assume X and Y are feature matrices of m different samples, K=XX^T, L=YY^T, then using the definition of Hilbert-Schmidt independence criterion (HSIC), the CKA is defined as follows:

The more similar X and Y are, the higher the CKA value is. More details of the definition can be found in Sec. 3 of the paper.
With the definition of CKA, a natural question arises: how similar the features from different layers of the ViT and CNN are? The authors showed that the patterns are quite distinct — ViT has a more uniform feature representation across all layers, while the CNN/ResNet50 has a grid-like pattern across lower and higher layers. This means the ResNet50 is learning different information between its lower and higher layers.
But what is the “different information” that ResNet is learning at its lower and higher layers? We know that for CNN models, due to the nature of convolutional kernels, only local information is learnt at lower layers and global information is learnt at higher layers. So it’s not surprising there is a grid-like pattern between different layers. Then we can’t help but ask, what about ViT? Does ViT also learn local information at its lower layers?
If we take a further look at the self-attention head, we know that each token attends to all other tokens. Each other token being attended to is a query patch and is assigned an attention weight. Since two “tokens” represent two image patches, we can calculate the pixel distances between them. By multiplying the pixel distance and attention weight together, an “attention distance” is defined. A large attention distance means most of the “faraway patches” have large attention weights — alternatively speaking, most of the attention is“global”. Inversely, a small attention distance means the attention is local.

The authors further investigated the attention distances within the ViT. From the result below, we can see that although attention distances from higher layers (block 22/23, highlighted by red) contain mostly global information, however, even the lower layers (block 0/1, highlighted by red) still contain global information. This is totally different from the CNN models.
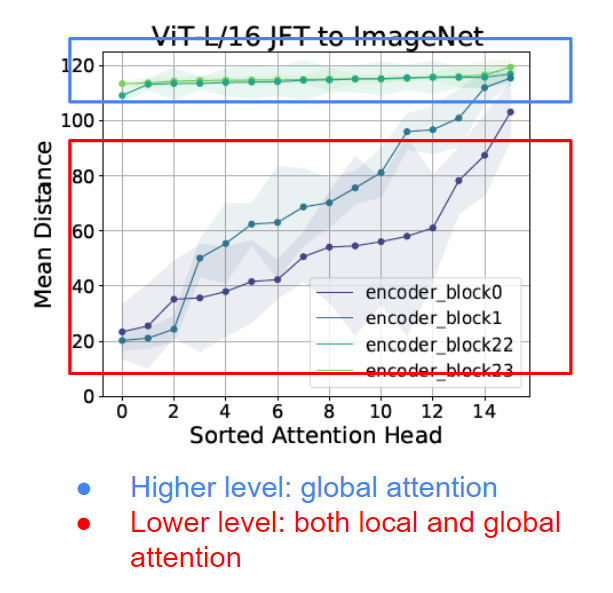
Now we know that the ViT learns global representation even at its lower layers, the next question to be asked is, do these global representations propagate faithfully to its higher layers? If so, how?
The authors claimed that the key is the skip connection of the ViT. The skip connection exists both at the self-attention head and the MLP head for each block. The authors further defined a metric, the Ratio of Norms (RoN), by dividing the norm of the features passing through the skip connection over the norm of the features passing through the long branch. They found the astonishing phase transition phenomenon, where the RoN is high for the classification (CLS) token at lower levels and much lower at higher layers. The pattern is inverse for spatial tokens, where RoN is lower at lower layers.

If they further remove the skip connection at different layers of ViT, then the CKA map would look like the following. This means the skip connection is one of the main (if not all) mechanisms that is enabling the information flow between different layers of ViT.
Besides the powerful skip connection mechanism and the ability to learn global features at lower layers, the authors further investigated the ability of the ViT to learn precise location representation at higher levels. This behaviour is very different from ResNet as Global Average Pooling could blur out the location information.
Also, the authors noted that a limited dataset could hinder ViT’s ability to learn local representations at its lower layers. Inversely, a larger dataset is especially helpful for ViT to learn high-quality intermediate layer representations.
